




描述
本产品是基于国内最新研发的SXM2双卡NVLink扩展方案,深度优化了电源、水冷散热系统与机箱结构的高性能专业计算平台。核心集成两块NVIDIA Tesla V100-SXM2-32GB 专业计算卡,提供卓越的并行计算能力:
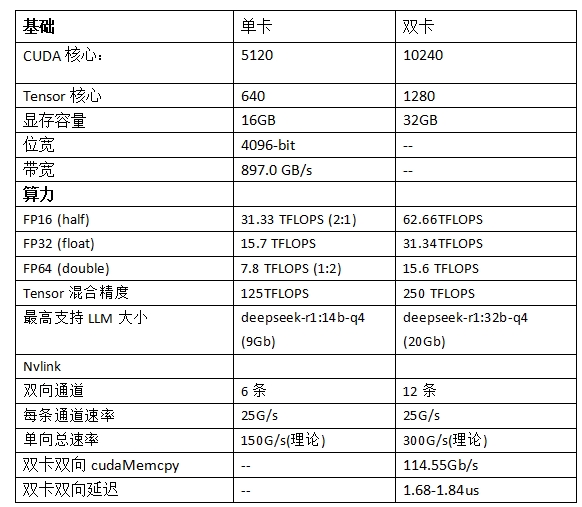
- 强劲算力核心: 双卡合计拥有 10,240 个 CUDA 核心 和 1280个 Tensor 核心,专为加速科学计算、AI训练与推理、高性能计算(HPC)等负载设计。
- 高速大显存: 配备总计 64GB HBM2 显存,提供高达 900 GB/s 的显存带宽(单卡),显著优于消费级显卡的GDDR6/GDDR6X方案,有效应对大规模数据集和复杂模型。
- 专业计算优势: V100 提供领先的 FP64(双精度) 和 FP16/TF32(混合精度) 计算性能,并支持 NVIDIA NVLink 高速互连技术,使其在专业计算领域(如CAE仿真、计算流体力学、分子动力学、深度学习训练)的性能和价值远高于 GeForce RTX 3090/4090 等消费级旗舰显卡,后者主要优化单精度和游戏性能,且缺乏原生高速多卡互连能力。
突破性的 NVLink 互连性能
本产品通过创新的设计,绕过了传统 PCIe 通道的限制:
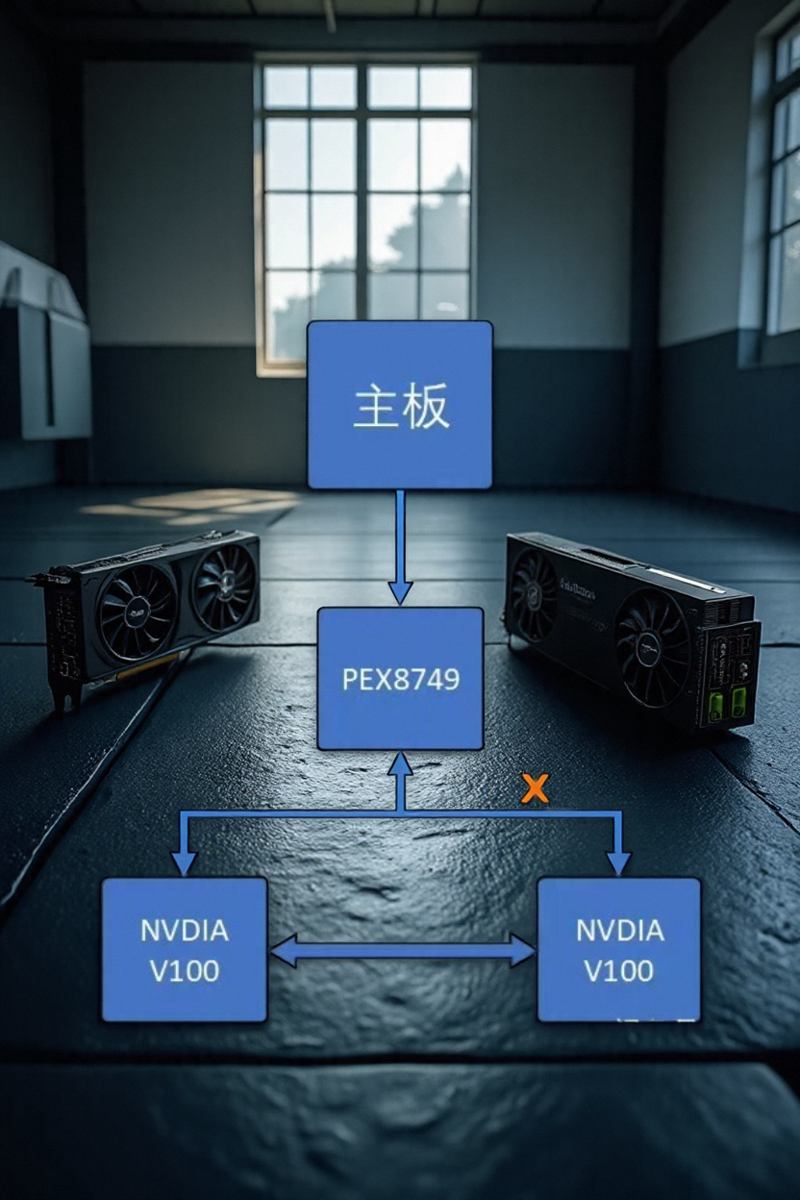
- 利用 PEX8749 交换芯片,将主机的一条 PCIe 3.0 x16 插槽 逻辑拆分为两条独立的 PCIe 3.0 x16 通道,分别连接至两块 V100 显卡。
- 两块 V100 显卡之间通过专用的 6 通道 NVLink 2.0 桥接器进行直接高速互连,提供高达 300 GB/s 的双向总带宽。
- 这种设计确保了双卡之间的数据交换速度远超 PCIe 3.0 x16 (约 16 GB/s 单向带宽),充分发挥了 V100 NVLink 互连的极致性能,显著提升多卡协同计算效率。
便捷部署与灵活扩展
* 即插即用: 只需将产品附带的转接卡插入主机任意一个 PCIe x16 插槽,操作系统即可自动识别两块独立的 V100 显卡,无需额外安装转接卡驱动,部署极其简便。
* 强大扩展性: 得益于独立的主机接口设计,本产品可轻松接入具备多个 PCIe x16 插槽(需满足物理空间和供电要求)的服务器或工作站。用户可灵活部署多组双卡盒子,实现 4卡、8卡 甚至更大规模的专业算力池构建,满足不断增长的计算需求。
整体性能
- 双卡聚合算力: 提供顶级的 FP32/FP64 浮点性能和 INT8 推理性能,特别适合 HPC、AI 训练/推理、CAE 仿真、科学计算等专业负载。
- 极致通信带宽: 双卡间 300 GB/s 的 NVLink 带宽,是构建高效能多 GPU 系统的关键,显著优于依赖 PCIe 互联的方案。
- 稳定可靠运行: 专业级水冷散热和优质电源保障双卡长时间高负载稳定运行。
- 高密度算力部署: 模块化设计极大节省空间,简化大规模集群部署和管理。
产品规格
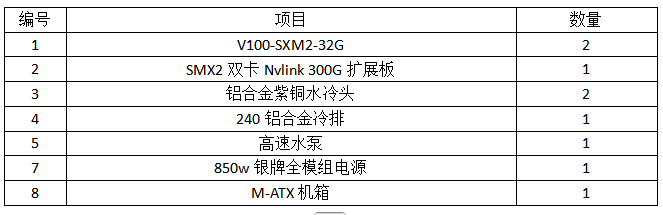
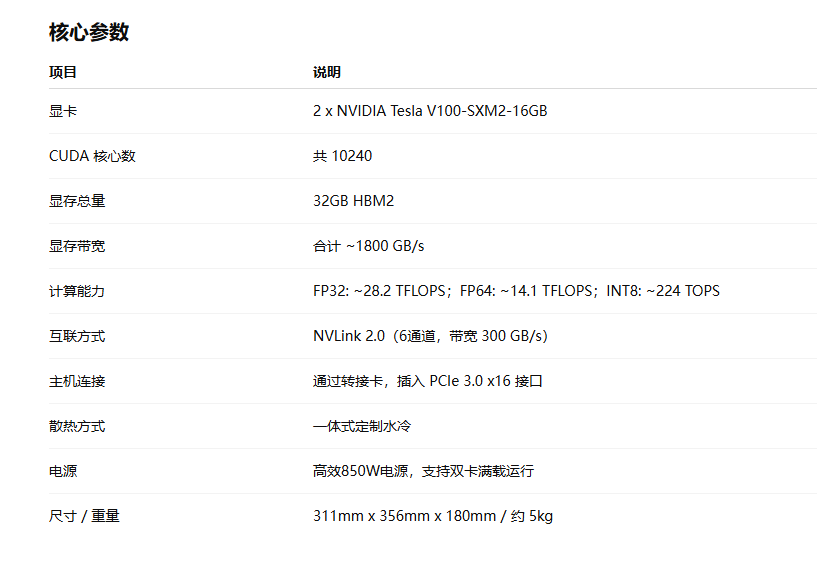
- GPU: 2 x NVIDIA Tesla V100-SXM2-32GB
- CUDA 核心: 10240 (2 x 5120)
- 显存: 64GB HBM2 (2 x 32GB)
- 显存带宽: ~1800 GB/s 聚合 (2 x ~900 GB/s)
- 计算性能 (峰值):
- FP32: ~28.2 TFLOPS
- FP64: ~14.1 TFLOPS
- INT8: ~224 TOPS
- 互联技术: NVIDIA NVLink (Gen2), 6 通道
- 卡间带宽: 300 GB/s (双向)
- 主机接口: PCIe 3.0 x16 (通过 PEX8749 拆分为 2x PCIe 3.0 x16 连接 GPU)
- 散热方式: 定制一体式水冷
- 电源: 集成高功率高效850W电源模块 (满足双卡 TDP 600W+ 及系统需求)
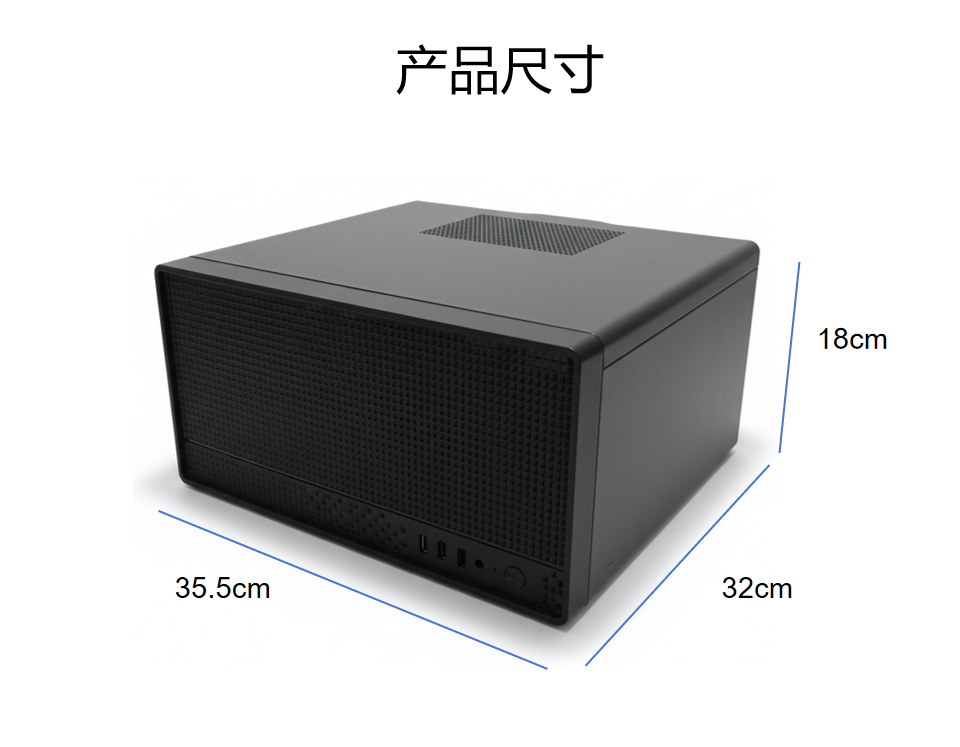
- 外形尺寸:311mm x 356mm x 180mm
- 重量: ~5kg
适用场景
- 人工智能与深度学习:
- 大规模深度学习模型训练 (尤其受益于 NVLink 高速互联和 FP16/FP32 性能)。
- 高性能 AI 推理 (INT8)。
- 自然语言处理 (NLP)、计算机视觉 (CV) 研究与应用。
- 高性能计算 (HPC):
- 科学计算与仿真 (CAE, CFD, FEA – 尤其受益于高 FP64 性能)。
- 分子动力学模拟、计算化学、物理模拟。
- 金融建模与风险分析。
- 专业渲染与虚拟化:
- GPU 加速渲染 (V-Ray, Redshift, Octane 等)。
- Virtual GPU (vGPU) 应用,为多个用户提供强大虚拟工作站。
- 数据中心与云计算:
- 构建高密度、高能效的 GPU 计算节点。
- 提供按需的云端 AI/HPC 算力服务。
- 需要超越消费级显卡 (如 3090, 4090) 的专业计算能力、双精度性能、大显存容量以及多卡高速互联的场景。
硬件规格
GPU: 2 块 Tesla V100 16G/32G
GPU显存: 32G/64 GB 系统显存总容量
Nvlink速率:300G/s
噪音: < 40 dB
重量: 2 Kg
系统尺寸 311mm x 356mm x 180mm
最大功率:600 W
V100核心运行温度范围:37–80 °C
适用操作系统 :Ubuntu/Windows
Tesla V100 Dual Card Water Cooling Graphics Card Dock
External graphics card with 32G memory and NVLink, meeting all your requirements for V100 dual card NVLink. Lightweight, compact, quiet, and powerful.
Comparable to 3090-24G and 4090-24G, with the same 10,000 CUDA core configuration, our 32G memory outperforms them.
Can run various 32B-Q4 large models directly.
With an additional 16G or higher NVIDIA graphics card in the host, you can run any 70B-Q4 quantization model.
In stock, ships immediately via SF Express.
Using the PEX8749 chip, one PCIe 3.0 x16 channel is split into two PCIe 3.0 x16 channels, and then connected to the motherboard via NVLink 6-channel dual-way 25G full-speed connection, with a data transfer rate of 300G between the two V100 cards.
Dual 240mm radiator water cooling configuration, silent operation, cooling two 300W V100 cards, with a daily operating temperature not exceeding 47°C and a full-load V100 core temperature not exceeding 60°C.
Body size: 40 x 20.5 x 41 cm
Internal: 2 x 240mm radiators
Water cooling head: Aluminum alloy heat sink + copper core + acrylic body
Water pump: High-speed submerged pump
V100 combination scheme:
- 16G + 16G = 32G
- 16G + 32G = 48G
- 32G + 32G = 64G
Introduction:
This is a high-performance computing and AI training platform, built with the latest domestic SXM2 dual-card NVLink expansion scheme. It integrates two NVIDIA Tesla V100-SXM2 16GB professional graphics cards, with a water cooling system, optimized power supply, and structural design, easily handling large-scale AI training, scientific simulations, and other heavy-duty tasks.
Why choose this product?
Ultra-powerful computing, professional calculation tool
Equipped with two Tesla V100 graphics cards, with a total of 10,240 CUDA cores and 640 Tensor cores, designed for scientific computing, deep learning, and high-performance simulations.
Total memory capacity reaches 32GB high-speed HBM2 memory, with a bandwidth of up to 900GB/s (single card), far surpassing ordinary graphics cards, easily handling large models and big data.
High-speed interconnection, double efficiency
Two graphics cards connected via NVLink 2.0, with a data transfer bandwidth of up to 300 GB/s (dual-way), far faster than traditional PCIe interfaces, effectively improving multi-card collaboration efficiency.
Using the advanced PEX8749 chip, one PCIe slot can connect two independent graphics cards, breaking hardware limitations.
Plug-and-play, easy deployment
System automatically recognizes the card after insertion, no need for additional drivers, quick deployment.
Can be flexibly expanded, supporting multiple devices to form 4-card, 8-card, or more GPU computing clusters, adapting to growing business needs.
Powerful water cooling system, stable operation
Customized water cooling scheme, combined with efficient power supply, ensuring stable operation of the dual cards under high load.
Modular design saves space, suitable for data centers or laboratory environments.
Note:
- V100 power consumption is 300W, HBM heat generation is huge, and air cooling is difficult to suppress. Water cooling is recommended to avoid damaging the core and HBM memory.
- Original driver installation guidance is provided, with no driver drop, and a guarantee of lighting up.
- Water cooling fan, cold cover, NVLink conversion card (non-human damage) are warranted for 6 months.
- Formal invoice: general invoice + 6%

